
Technical Data
技术资料
癌症的早期诊断对癌症的治疗非常关键,血液也成为临床上癌症早期生物标志物筛选的理想样本。蛋白组学技术的日益精进推动了癌症生物标志物的筛选,但目前的研究还仅仅停留在单一癌症类型的标志物研究。2018年5月29日,Rueda Aebersold团队在Cell Reports上发表了最新研究成果,他们利用SWATH/DIA 技术比较了5种不同类型原位癌及其对照组间的血浆糖蛋白组的变化,第一次在一次实验中同时比较分析不同癌症类型间蛋白组变化的异同。他们发现不同的癌症类型都会分泌血管生成调控相关的蛋白,同时也发现了与癌症类型相关的特异性变化的蛋白。他们首次建立的不同癌症类型的N-糖蛋白数据库以及N-糖肽谱图库为今后的癌症研究提供了参考资源。
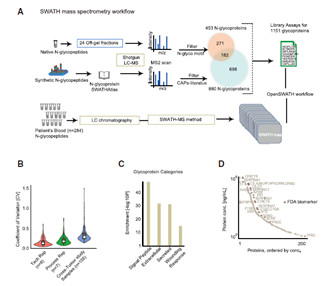
首先作者挑选了5种原位癌,分别是结直肠癌、胰腺癌、肺癌、前列腺癌以及卵巢癌,每种癌症都有年龄、性别匹配的健康对照,每组样本约15-20例。为提高低丰度蛋白的鉴定效率,作者采用经典的酰阱技术捕获糖蛋白,并用PNGase F酶特异性切除N-糖基化的糖肽。研究表明,该糖肽捕获技术能够提高质谱检测灵敏度至ng/mL级别(图1A)。
作者利用SWATH/DIA技术首先对155例血液样本(癌症+对照)进行了大规模筛选,又在85例前列腺癌以及45例胰腺癌中进行了验证。由于SWATH/DIA技术依赖预先建立的DDA谱图库进行数据分析,肽段信息丰富且高质量的谱图库对SWATH/DIA数据分析至关重要。本实验中DDA糖肽谱图库建立的样本来源于1)1604个合成的糖肽,以及2)混合血液样本中富集的糖肽。每个样本中掺入iRT (Biognosys)标准肽用于保留时间校准。最终建好的DDA糖肽谱图库中包含4347个N-糖基化肽段,涉及1151个糖蛋白。
经过DDA建库以及SWATH/DIA质谱检测,作者一共鉴定到1444个N-糖基化肽段,其中1360个N-糖基化肽段在至少2/3的样品中被定量到,覆盖203个糖基化蛋白,丰度跨越~7个数量级。本实验中,SWATH/DIA对血液样品的定量呈现出了优异的技术重复性(r=0.96-0.98)以及生物重复性(r=0.92-0.94)(图1B-D)。
不同类型的癌症及对照组并不能在层次聚类分析(Hierarchical clusteranalysis)中得到明显的归类,说明癌症内部及癌症间的异质性以及人群的个体差异性很大。

差异蛋白分析发现,癌症早期,蛋白表达变化并不明显,90%的蛋白倍数差异在1.2倍以内,因此作者将1.2倍,p<0.05 作为差异蛋白的临界点。其中一些差异蛋白在多种癌症中出现,尤其是THBS1,在4中癌症中出现。这些共同出现的差异蛋白均跟血小板激活相关,而THBS1跟血小板激活蛋白相关性最强,这些现象说明不同癌症间存在共性,体现为血小板蛋白表达的变化。

基于血浆N-糖基化蛋白组的随机森林分析,可以有效的将胰腺癌(86% out of bag accuracy)和前列腺癌(65% out of bag accuracy)与其对照组区分,但其他癌症区分度较差。其中胰腺癌和前列腺癌的标志蛋白间有一半相似,一半为癌症类型特异性蛋白。

ROC曲线显示,同时在多种癌症中表达的THBS1能够同时很好的区分前列腺癌、卵巢癌、结直肠癌以及肺癌,而FN1也能够区分胰腺癌、前列腺癌以及肺癌。相反,特异性的在胰腺癌中的表达的PIGR仅能区分胰腺癌,在胰腺癌中特异性表达的PZP仅能区分前列腺癌。

因为在随机森林分析中,前列腺癌和胰腺癌与对照组间有较好的区分度,因此作者又针对两种癌症的新样品对潜在的糖蛋白标注物进行了验证。他们同样采用SWATH/DIA质谱采集模式。结果发现,FN1,ITIH2,CNDP1以及PIGR能够同时区分发现阶段和验证阶段的胰腺癌样品;PZP以及THBS1能够区分发现阶段和验证阶段的前列腺癌样品。

结一下,本文利用SWATH/DIA 结合糖蛋白富集技术,发现不同癌症存在共性及特异性的差异蛋白。结合共性及差异性的蛋白作为生物标志物,能够较好的区分胰腺癌及前列腺癌。同时他们首次建立的不同癌症类型的N-糖蛋白数据库以及N-糖肽谱图库为今后的癌症研究提供了参考资源。
关注我们
服务热线: 18221381405
关注公众号
咨询微信客服

